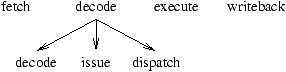
However, in-order execution does not fully utilize all functional parts of a CPU. The rule of in-order execution prohibits that subsequent instructions overtake previous instructions. In figure 2.1, instruction I2 blocks the execute stage for four cycles, since the division function unit has a long latency. Instruction I3 has to be stalled upon the begin of its execution, since the execution stage is blocked by I2 and since it requires the result of I2 (data dependence).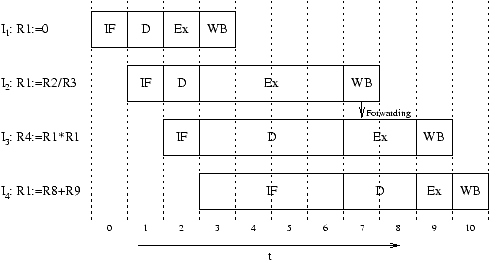
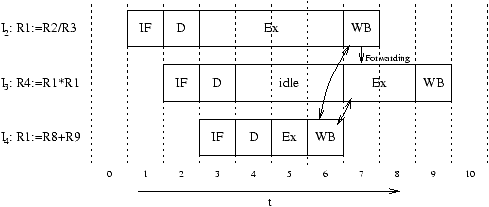
Figure 2.2: Out-of-order execution example. Instructions I2 and I4 cause a WAW hazard, instructions I2 and I3 cause a RAW hazard, and instructions I3 and I4 cause a WAR hazard.
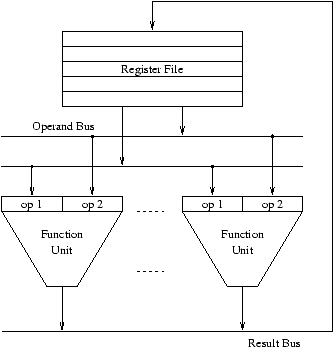
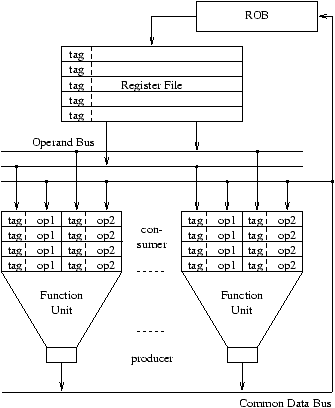
Figure 2.3 gives an overview of the basic data paths of an in-order design and of the same design after adding Tomasulo scheduling with reorder buffer. The Tomasulo scheduling algorithm requires the following data structures and transfer paths:
Basic structure of an in-order design After adding Tomasulo scheduling
The reservation stations provide the operands for the function units. They are basically a queue for the issued instructions. Each reservation station RSi holds exactly one instruction and its operands and has the following components (figure 2.4):
When an instruction completes, both the result and the exception flags are written into the reorder buffer entry pointed to by this reorder buffer tag. In each cycle, the entry at the head of the reorder buffer is tested. If it is valid (i.e., the instruction has completed), a check for exceptions is performed and the data is written into the register file. Depending on the type of the interrupt (abort/repeat/continue), the result of Ii is written into the register file before executing the interrupt service routine.
Name Width Purpose valid 1 valid =1 Û data field contains a valid value data 64 result data dest 4 address of the destination register
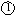 (figure 2.5). If so, the instruction is issued
into this reservation station entry -0.5ex
(figure 2.5). If so, the instruction is issued
into this reservation station entry -0.5ex
 . For each operand of the
instruction three sources have to be checked -0.5ex
. For each operand of the
instruction three sources have to be checked -0.5ex
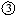 : The operand
might be in the register file -0.5ex
: The operand
might be in the register file -0.5ex
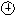 , on the CDB -0.5ex
, on the CDB -0.5ex
 , or in
the reorder buffer -0.5ex
, or in
the reorder buffer -0.5ex
 . If not, it is the destination of a
preceding, incomplete instruction -0.5ex
. If not, it is the destination of a
preceding, incomplete instruction -0.5ex
 , and instead of the operand,
the tag of this instruction is stored in the reservation station.
, and instead of the operand,
the tag of this instruction is stored in the reservation station. . If the instruction has a destination register, the address of
this register is stored in the ROB entry and the pointer to the ROB entry is
stored as tag in the producer table. After issue, the tail pointer is
incremented -0.5ex
. If the instruction has a destination register, the address of
this register is stored in the ROB entry and the pointer to the ROB entry is
stored as tag in the producer table. After issue, the tail pointer is
incremented -0.5ex
 .
. .
Furthermore, the function unit must not be stalled, i.e., it must be ready
to accept a new instruction. If more than one instruction for a certain
function unit is valid, the scheduler has to choose one for dispatch. The
correctness proof in chapter
6 relies on choosing the oldest among the valid
instructions. This issue is discussed in chapter 3. If all
these conditions hold, the instruction is passed to the function unit
-0.5ex
.
Furthermore, the function unit must not be stalled, i.e., it must be ready
to accept a new instruction. If more than one instruction for a certain
function unit is valid, the scheduler has to choose one for dispatch. The
correctness proof in chapter
6 relies on choosing the oldest among the valid
instructions. This issue is discussed in chapter 3. If all
these conditions hold, the instruction is passed to the function unit
-0.5ex
 and the reservation station is freed
-0.5ex
and the reservation station is freed
-0.5ex
 .
. , the result and the ROB tag are put on the CDB -0.5ex
, the result and the ROB tag are put on the CDB -0.5ex
 .
The according reorder buffer entry is filled with the result and the valid
bit is set -0.5ex
.
The according reorder buffer entry is filled with the result and the valid
bit is set -0.5ex
 .
. , if no
interrupt of type abort or repeat is pending -0.5ex
, if no
interrupt of type abort or repeat is pending -0.5ex
 .
. . Almost all
result flags are masked with the SR registers prior this check. If an error
occurred while processing the instruction, the interrupt service routine is
started. Section 3 contains more details of the interrupt mechanism.
. Almost all
result flags are masked with the SR registers prior this check. If an error
occurred while processing the instruction, the interrupt service routine is
started. Section 3 contains more details of the interrupt mechanism.
ALU reservation station for I2 register file t global operand 1 operand 2 R1 R2 R3 op tag full tag valid data tag valid data tag valid data tag valid data tag valid data 0 - - 0 - - - - - - - 1 0 - 1 9 ROB-0 0 - 1 + ROB-1 1 - 1 9 ROB-0 0 - ROB-1 0 - - 1 9 ROB-0 0 - 2 + ROB-1 1 - 1 9 ROB-0 0 - ROB-1 0 - - 1 9 ROB-0 0 - 3 + ROB-1 1 - 1 9 ROB-0 1 11 ROB-1 0 - - 1 9 ROB-0 0 - 4 - - 0 - - - - - - ROB-1 0 - - 1 9 ROB-0 0 - 5 - - 0 - - - - - - ROB-1 0 - - 1 9 - 1 11 6 - - 0 - - - - - - - 1 20 - 1 9 - 1 11
reorder buffer common t global entry 0 entry 1 data bus ROB.head ROB.tail valid data dest valid data dest req ack tag valid data 0 ROB-0 ROB-1 0 - gpr R3 - - - - - - - 0 - 1 ROB-0 ROB-2 0 - gpr R3 0 - gpr R1 - - - 0 - 2 ROB-0 ROB-2 0 - gpr R3 0 - gpr R1 Mem - - 0 - 3 ROB-0 ROB-2 0 - gpr R3 0 - gpr R1 ALU Mem ROB-0 1 11 4 ROB-0 ROB-2 1 11 gpr R3 0 - gpr R1 - ALU ROB-1 1 20 5 ROB-1 ROB-2 - - - - 1 20 gpr R1 - - - 0 - 6 ROB-2 ROB-2 - - - - - - - - - - - 0 -